As the evolution of data management, and specifically the data lake, continues at an ever increasing rate, we took a look back at where data management has been – and to understand how to get more out of data lakes, it helps to understand how the industry has gotten to this point in its data management methods.
From the 1970s until about the year 2000, as firms switched from manual to mainframe-based electronic processes, financial services industry data mostly resided in siloes. This meant that data related to a business system was stored in that system or in a silo dedicated to that system. This prevented standardization of data, because firms would have different identifiers for the same data in different locations, which in turn lead to reconciliation issues on reporting. Data easily became stale and no central control was possible.

The new millennium
By the turn of the new millennium, with the advent of centralized messaging (Enterprise message bus architectures), centralization of data and data standards became possible, hence the advent of more sophisticated data management – enterprise data management (EDM) and master data management (MDM) systems. Data was centralized, and the concepts of golden copy, data labeling, governance, lineage, and data standardization started being applied. Around 2010, in the financial domain the idea of a data warehouse came to the forefront. This complemented EDMs, MDMs and standardization with its flat data structure for easier data access and reporting.
The aftermath of the financial crisis brought the need for accelerated analytics to the forefront. In an analytics world, data availability and ease of quick loading are paramount. The localized data warehouse became the tactical solution to this requirement.
A fly in the ointment still buzzed, however, and that was what to do about exceptions. In an extract transfer load (ETL) process, which validates data before it is loaded into a warehouse, service-level agreements (SLAs) became necessary to make sure exceptions kicked out in an ETL process were fixed in a timely manner to support business operations and processes.
Also, it is not necessary for all data to go through validation processing, either because of the type of data, or the fact that it may end up not being required once validated. Furthermore, with growing volumes of unstructured data, including that from the internet and social media, even the data handling capabilities of data warehouses became limited for advanced analytics – hence the advent of the data lake.
The advent of the data lake
A data lake is a data store for structured and unstructured data that enables business applications to easily access and use the data. Users can manage more data at scale and produce more types of analytics about that data than they could in previous storage designs. As a result, over the past few years, the data lake has emerged as the latest growth technology in the data storage and management field.
Many initial implementations of data lakes have had growing pains. Having such a large data storage potential but with limited overarching structural options led to data cataloging and extraction issues, so much so that terms like “data swamp” and “data graveyard” became commonly used. Without well designed data schemas they still fell short of the “ideal” of having rapidly ingested, natively scaled, enriched with domain symbology, all without major amounts of effort.
The latest incarnation, however, the lake house/delta lake concept, now offers a series of new features to help. To address the complexity and allow for all data to be loaded directly, the data lake house or delta lake emerged as a hybrid between EDMs and data warehouses, offering both structure and operational refinement with easy analytical data extraction. This also introduced the ELT concept of extract, load and then validate post-load, allowing all data to be loaded before rules are applied, removing the exception-at-ingestion overhead. It does this by having a series of data storage zones to better organize data and keep a tight track on its lineage – critical to deep data analytics.
So the modern data lake house makes it possible for users to easily query data from a warehouse, process it and report on it. The concept has been around for several years, but only more recently caught on with firms beginning to use it.
Where are we now?
Over the past 18 months, lake houses turned into a “revolution” as more chief data officers turned to their capability, and the use of lake houses began permeating throughout enterprises.
However, this solves only part of the problem when it comes to financial data sets. By definition, to have a rich data store you need data from a wide variety of data sources: vendor, internal, exchange, custodian, and others, which leads to its own challenges. For example, any data point could be stored multiple times in multiple formats with no cross referencing or common dictionary allowing for easy access/extraction.
In a well-designed data lake, the data residing in the structured (silver) or curated (gold) zones would have a standard format, allowing for direct comparison by source, extraction and rules to be applied. It should have a dictionary to allow other applications and developers to easily access and reference the data, ideally with a symbology as part of its design, allowing for grouping and extraction as required. Finally a governance layer should exist within the model to describe things such as data quality, data lineage, and security around the data.
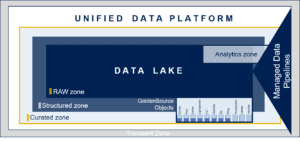
Pipeline or Native Processing in a Data Lake
A data lake house model can bring benefits in two ways: by enabling the building of native applications to manage data over the lake, or by leveraging an array of data pipeline services which interoperate outside of the lake populating the required layers and required metadata.
Either way, the target is to arrive at a unified platform where analysis can be performed no matter whether data is raw, structured, or curated.
You will want your data lake house model to make data available – make all the stages of the data available, not just an end result. In this model, a data lake collects all the previous stages of your data then accounts for how orders may change that data. Working with a data lake this way gives users source data, semi-transformed data, transformed data and then an end result, including all the operations that data has gone through. All of this gets delivered transparently, making it easy to determine why errors happened if they have, by replaying data changes and using what-if analysis. These methods would be hard to do without this data lake house model.
While data lakes have an advantage in speed of processing, they need better organization and governance, so the lake house model addresses that.